Marie-Christine Bruneau
Marie-Christine Bruneau 
Les avancées en intelligence artificielle révolutionnent le processus de recherche marketing. Découvrez quelques-unes de ces nouvelles pratiques pour demeurer concurrentiel.
Il devient difficile de nos jours d’exploiter une entreprise sans adopter une approche centrée sur le client qui place les données au cœur de sa stratégie d’affaires. L’acquisition de données par la recherche marketing est largement répandue et leur exploitation efficace est indispensable pour demeurer compétitif. Dans un monde où l’intelligence artificielle (IA) se taille une place de plus en plus avérée au sein des méthodes de travail, ce domaine ne fait pas exception. Quelles pratiques novatrices les organisations peuvent-elles intégrer pour demeurer concurrentielles ? Voici trois exemples inspirants présentés lors du congrès annuel d’ESOMAR qui s’est tenu à Athènes en septembre 2024.
Demeurer branché sur l’innovation grâce à ESOMAR
Le congrès annuel organisé par l’association ESOMAR, dédiée à l’excellence de la recherche marketing, rassemble des professionnels et des fournisseurs de services du monde entier. Cet événement offre une vitrine précieuse pour échanger sur les dernières innovations en recherche, tant quantitative que qualitative, et pour découvrir des initiatives intéressantes et des études de cas innovantes. Les représentants de l’industrie touristique sont malheureusement peu nombreux à fréquenter ce genre d’événements, mais gagneraient à le faire.
Les robots conversationnels au service de la stratégie de responsabilité sociale et environnementale
Un exemple marquant présenté lors de la conférence est celui du géant de télécommunications Orange qui a développé des robots conversationnels virtuels alimentés par l’IA pour l’aider à déployer sa stratégie de responsabilité sociale et environnementale (RSE). Au total, quatre persona ont été créés à partir de données clients quantitatives et qualitatives qu’Orange possédait déjà. Ils représentent ainsi l’incarnation artificielle de quatre de ses segments de clients, en fonction de leur sensibilité et intérêt envers la RSE.
En conversant par écrit avec ces robots, les employés sont en mesure de rapidement prétester de nouvelles idées, sans devoir mener d’enquêtes ou organiser des groupes de discussion. Par exemple, les équipes marketing peuvent mesurer l’intérêt pour une nouvelle offre, évaluer le produit le plus porteur pour chacun des segments de clientèle ou tester la compréhension d’un message publicitaire.
L’image présentée ici-bas suggère ainsi que les clients appartenant au segment « Actives » démontrent un intérêt plus marqué que les autres segments envers les téléphones intelligents reconditionnés et qu’ils apprécient particulièrement le fait qu’ils aient un impact moindre sur l’environnement.

Source : photo personnelle de l’auteure, septembre 2024.
À noter que les concepts sont toujours testés auprès de clients réels par la suite.
Cette méthodologie comporte, bien entendu, des limites :
- l’entreprise doit posséder des données clients valides ;
- les robots ont tendance à exprimer des opinions plutôt conformistes ;
- leur portée est limitée à ce pour quoi ils ont été programmés, soit pour se prononcer sur des produits liés à la responsabilité sociale et environnementale.
Les données synthétiques pour améliorer la qualité des enquêtes menées en ligne
Les données synthétiques étaient l’une des thématiques phares de la conférence ESOMAR.
L’événement a notamment mis en lumière l’utilisation croissante de ce genre de données qui sont générées artificiellement à partir de données existantes, plutôt que collectées auprès de répondants réels. Elles représentent une alternative intéressante dans un contexte où les participants frauduleux semblent de plus en plus répandus au sein des panels privés. Ces derniers proposent une banque de répondants prêts à répondre à toutes sortes d’enquêtes moyennant une rémunération. Une large portion de la recherche menée en ligne auprès de consommateurs est issue de ces panels. Or, les pirates informatiques n’épargnent aucune industrie. Au cours de la conférence, des chercheurs ont mentionné avoir identifié des proportions variables de répondants frauduleux au sein de certains échantillons, allant de 10 % jusqu’à 40 % ! Cela a le potentiel d’engendrer un effet désastreux sur les résultats d’une enquête et sur les actions stratégiques qui en découlent.
Les données synthétiques pourraient, non seulement aider à renforcer la validité des résultats d’une enquête menée en ligne, mais renforcer la faisabilité d’un projet en permettant d’augmenter le nombre de répondants issus d’un segment sous-représenté ou plus difficile à rejoindre. Elles sont également pressenties pour diminuer les coûts associés à une collecte de données et favoriser la rapidité d’exécution. On peut ainsi combler les données manquantes des répondants qui n’auraient pas rempli l’ensemble du sondage ou corriger a posteriori toute erreur de programmation.
Mais ces données sont-elles fiables ? L’entreprise Quest MindShare a examiné la qualité de données synthétiques qu’elle a générée en les comparant à l’échantillon réel. Une série de tests statistiques démontre un écart relativement faible entre les deux séries (en moyenne moins de 5 %). Cette proportion est encore moins élevée lorsque les données sont combinées au reste de l’échantillon.
L’image plus bas présente les principales variations de moyennes observées entre les données synthétiques, les données d’origine et les données combinées.
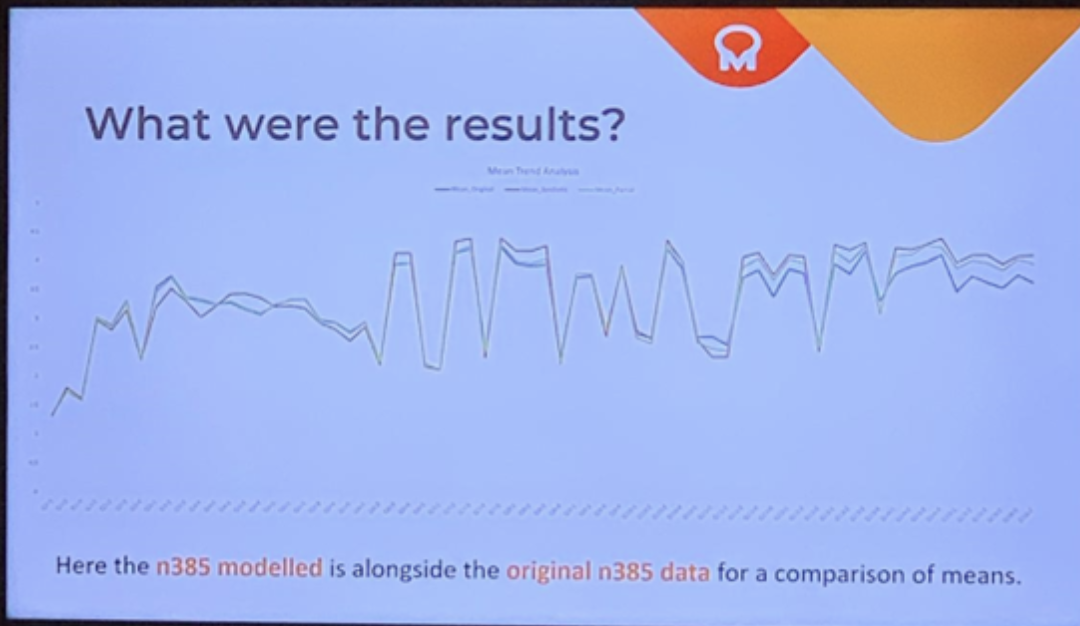
Source : photo personnelle de l’auteure, septembre 2024.
Des entreprises, notamment plusieurs « jeunes pousses », se spécialisent dans la création de ce genre d’échantillons. Parmi elles, l’entreprise Fairgen s’est distinguée lors de la conférence avec deux présentations particulièrement intéressantes portant sur l’utilisation des données synthétiques.
L’entreprise Ipsos, quant à elle, a même généré ce type de données pour modéliser les déplacements des Français, permettant ainsi de mieux orienter les placements média de ses clients en fonction de leurs cibles. Pourrait-on imaginer une telle utilisation pour modéliser les déplacements des visiteurs au Québec ?
L’IA pour détecter les répondants frauduleux au sein d’un échantillon en ligne
Les risques que représentent les répondants frauduleux, comme mentionné un peu plus haut, jettent une ombre sur l’utilisation de panels en ligne. Les professionnels de la recherche marketing sont déjà sensibilisés à l’enjeu de la qualité des répondants, étudiant habituellement les comportements problématiques ou divergents liés à la durée de complétion, la qualité des réponses ouvertes ou la logique des réponses données. Or, dans le contexte actuel, il semble nécessaire de développer un protocole plus serré. Des solutions visant à détecter les répondants frauduleux ont, par ailleurs, été développées par certaines compagnies pour offrir un résultat plus rapide, quoique plus coûteux.
À retenir pour intégrer l’IA dans vos pratiques de recherche !
- Si vous utilisez les services d’un panel privé pour mener vos enquêtes, assurez-vous d’aborder le sujet de la fraude avec votre fournisseur. Demandez à être informé des mécanismes mis en place pour s’assurer de la qualité des données colligées.
- Si vous souhaitez intégrer l’IA dans votre processus de recherche marketing, menez tout d’abord de petites expérimentations. Assurez-vous de tester la validité de celles-ci, de quantifier leur impact et de jauger leur intérêt pour votre entreprise.
- Si vous voulez explorer le potentiel des données synthétiques pour votre organisation, informez-vous davantage à ce sujet : soyez au fait des enjeux, des bonnes pratiques, des facteurs clés de succès et des limites. Et assurez-vous de la qualité des données qui seront utilisées pour les générer !
- Collaborez avec des experts en la matière : jeunes pousses, milieu universitaire, ou entreprises renommées spécialisées sauront bien vous encadrer !
Image à la une : photo personnelle de l’auteure, septembre 2024.